书接上文,昨天写完爬虫简易教程(一)后,室友连夜完成了他的种子爬虫1号。然而,在爬取的过程中,他发现有些网页链接并没有显式地写在网页中,我进一步确认后发现,网页链接是通过与后端数据库交互来获取,这样的动态页面就不能通过requests库来获取到所有需要的内容。为了解决这个问题,助力室友完成他的种子爬虫2号,这篇文章将介绍自动化测试工具selenium库,通过模拟浏览器的点击等操作实现链接的跳转,从而爬取到需要的内容。
配置Chrome驱动器
这里仅介绍Chrome浏览器的配置方法,selenium库还支持包括Firefox浏览器、IE浏览器、Edge浏览器等主流浏览器,配置方法类似,不再赘述。
下载Chrome浏览器
可以直接前往官网进行下载。
下载Chrome驱动器
首先在Chrome浏览器的地址栏中输入chrome://version,查看Chrome浏览器的版本号,我的版本号是107.0.5304.88。
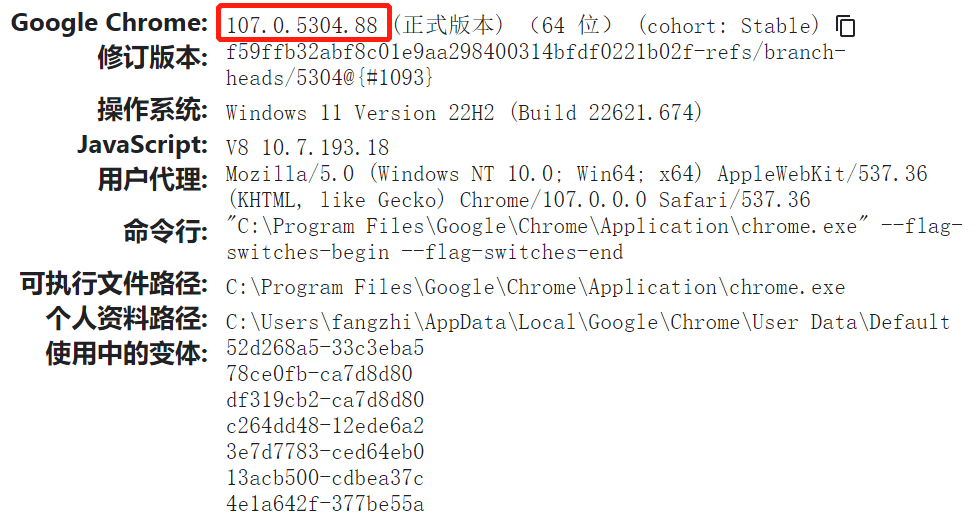
然后打开驱动器列表,找到适配浏览器版本号的最新的驱动器版本,我这里选择了107.0.5304.62版本。
将下载好的文件解压,得到chromedriver.exe文件,并将其放在与当前虚拟环境的Python解释器使用的python.exe文件相同的路径下。下面以Pycharm为例演示。
将鼠标悬浮在Pycharm窗口右下角解释器的位置。

可以显示解释器的路径,将chromedriver.exe文件放在同一路径下即可。

Selenium库的介绍
开始使用Selenium库
selenium库将浏览器自动化脚本进行封装,使其能够操纵浏览器实现启动、关闭、更改窗口大小、截屏、点击、悬浮、滚动等操作,就好像真的是用户在操作一样。
想要简单地使用selenium库实现网页爬取,可以参考以下代码。
1 | from selenium import webdriver |
如果想要获取并保存网页内容,可以使用如下代码。
1 | content = browser.page_source |
需要注意的是,一个Chrome()实例可以对应多个网页窗口的句柄,而对实例的任何操作都视为对实例中当前窗口的操作,正如一个浏览器中可以包含多个窗口,在浏览器中点击就视为在当前窗口点击。由于selenium有这样的特性,在实际运用时,不仅可以获取到网页窗口的内容,还可以与窗口甚至浏览器本身产生交互,从而达到更加灵活的效果。
Selenium库与窗口的交互
在使用requests库时,只需要打开窗口就可以爬取内容,这也导致requests库只能用来爬取静态页面的内容。Selenium库相较于requests库的最大优势就在于能够模拟浏览器,与窗口中的各个元素交互,从而能够爬取到动态页面的内容。例如,当某些内容需要登录后才能查看时,就可以使用Selenium库模拟登录操作,”欺骗“服务器返回需要的内容。从理论上来说,Selenium库能够模拟真人对于浏览窗口的所有操作。
1 | #-> 获取页面基本属性 |
更多的Selenium模拟键盘、鼠标、触摸笔、滚轮的操作参见官方文档。
定位元素并交互
定位元素可以直接使用以下代码,css语法和xpath语法详见爬虫简易教程(一),Selenium定位元素的语法糖详见官方文档。
1 | element = browser.find_element(By.CSS_SELECTOR, 'element') |
与元素交互有五种基本命令,下面给出简单的介绍,更详细的介绍参见官方文档。
1 | #-> 点击操作(适用于任何元素) |
iframe窗口
有时在定位元素时或与元素交互时会失败,这是由于存在iframe窗口。在这种情况下,需要先搜索并定位到iframe结点,切换到iframe窗口,再定位并与元素交互。
1 | iframe_node = browser.find_element(By.CSS_SELECTOR, 'iframe') |
如果想要切换出iframe窗口,可以使用以下代码。
1 | browser.switch_to.parent_frame() # 切换回上一级窗口 |
显式等待与隐式等待
对于静态页面,在页面加载完成后,所有的页面元素就都可以定位;但是对于动态页面,由于存在懒加载等机制,需要定位的元素或是需要滚动到页面底部、或是需要等待一段时间才能够定位。因此,如果在打开一个页面后立即定位某元素,很有可能定位失败,需要设置等待时间使元素能够加载出来。
设置等待时间的方法一般有两种:显式等待和隐式等待。显式等待指的是无论如何都要等待一段时间,在这段时间之后再进行定位操作,隐式等待则设定一个超时阈值,在超时之前轮询元素,在超时之前找到元素或者达到超时阈值都会结束定位元素的操作。下面是示例代码。
1 | # 显式等待,在需要等待的位置插入 |
Selenium库与浏览器的交互
1 | #-> 打开指定网页 |
无界面模式
使用上述代码编写的selenium自动化脚本在运行时模拟浏览器打开和关闭各种窗口,如果在运行时不希望显示这些窗口,可以使用selenium的无界面模式。一般来说,在调试时使用有界面模式,在运行正常后转为无界面模式。
1 | # 创建无界面模式的选项 |
使用cookie登录
与requests库一样,Selenium库同样可以携带cookie信息访问服务器。
以www.baidu.com为例,F12、Network、刷新、点击www.baidu.com、Cookies,能够得到下述界面。
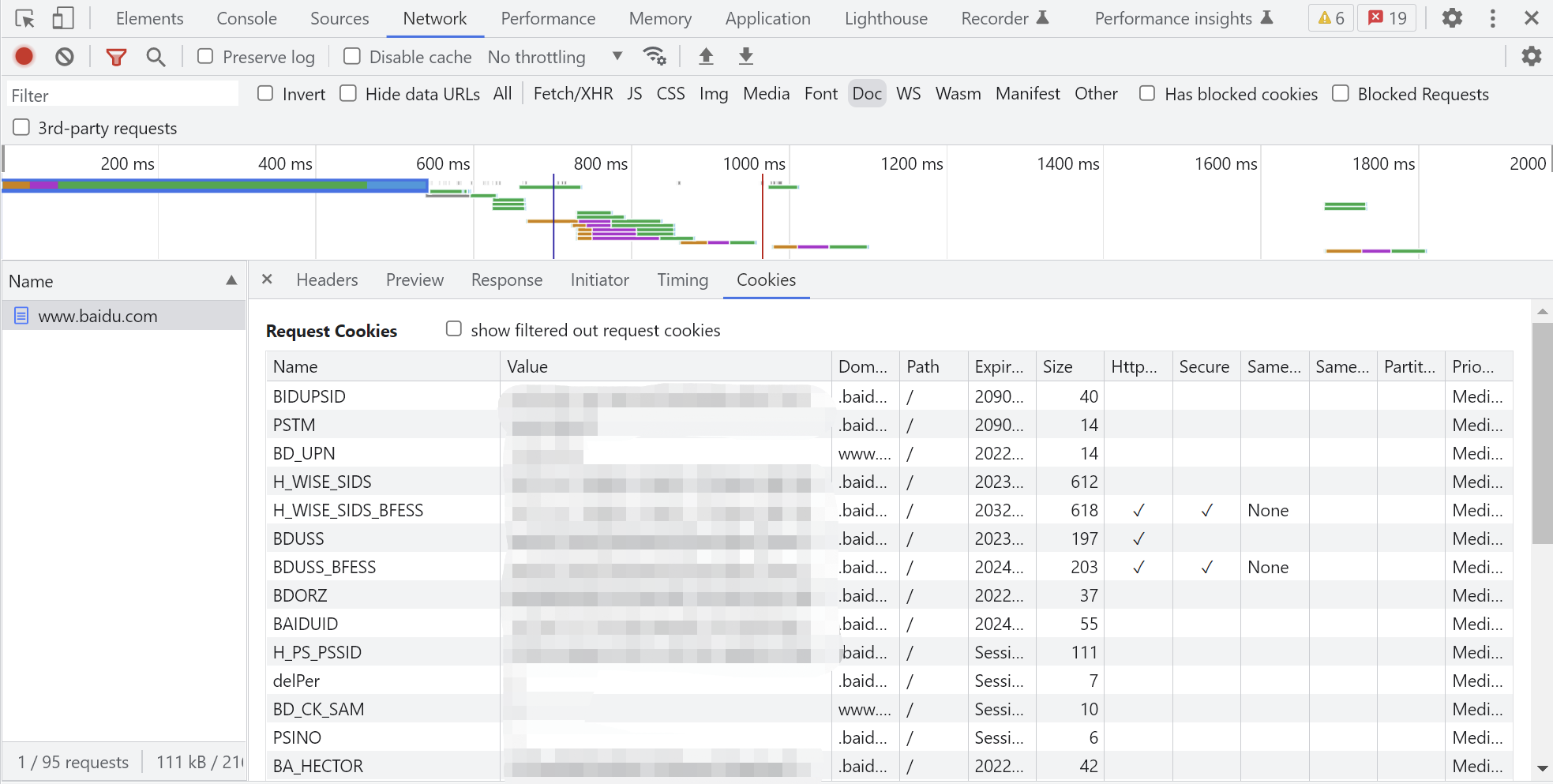
可以看到浏览器中cookie的表现形式,这里我们暂时只需要name和value。
同样地,使用爬虫简易教程(一)提到的方法提取cookie,能够得到下述界面。

可以发现两者是相互对应的。
Selenium库使用cookie的语法基于上述name和value,示例语法如下。
1 | # 添加cookie |