最近室友沉迷上了收集种子文件,总是问我如何用爬虫爬取种子文件,授人以鱼不如授人以渔,今天就来写一下如何创建爬虫程序来爬取网页上自己需要的资源。
爬虫程序的原理非常简单,一共分为三步:获取网页资源、筛选网页资源和保存网页资源。
获取网页资源
获取网页资源是爬虫程序的核心部分,仅在这一步需要与服务器交互,一旦得到网页内容,后续步骤均在本地处理。
为了获取网页资源,Python中常使用requests库和urllib3库,两者功能相似,这里仅对requests库加以介绍。
requests库中已经封装好了相应的方法,因此这里直接调用,以cnblogs为例进行爬取。
1 | import request |
进一步对响应内容进行解析,可以采用如下代码。
1 | content = response.content.decode('utf-8') |
这样就能够获取到cnblogs的页面内容了。为了加以验证,可以在浏览器中点击F12,在弹出的窗口中查看网页内容是否与获取到的内容一致,如果相一致说明获取页面内容成功。
筛选网页资源
获取得到的网页内容往往非常繁杂,为了在其中提取我们感兴趣的内容,需要进行进一步筛选。一般来说,筛选使用到的工具称之为“选择器”,而常用的网页选择器有两种:css选择器和xpath选择器,点击链接可以参考两者的语法,本文不再赘述。
两种网页选择器的原理都是将网页内容看作树形资源进行管理,每一块区域都看作树上的一个结点,均有其父结点,而最大的结点是<html>标签,代表整个网页区域。只要正确地按照选择器的语法给出筛选条件,就能够获取到自己感兴趣的区域内容。
唯一筛选内容
如果想要获取的内容是唯一的,可以方便地使用浏览器自带的鼠标选择工具进行点选:在浏览器中使用F12,在弹出窗口的左上角点击鼠标样式的按钮,即可点选网页内容,或直接使用ctrl+shift+c进行点选。
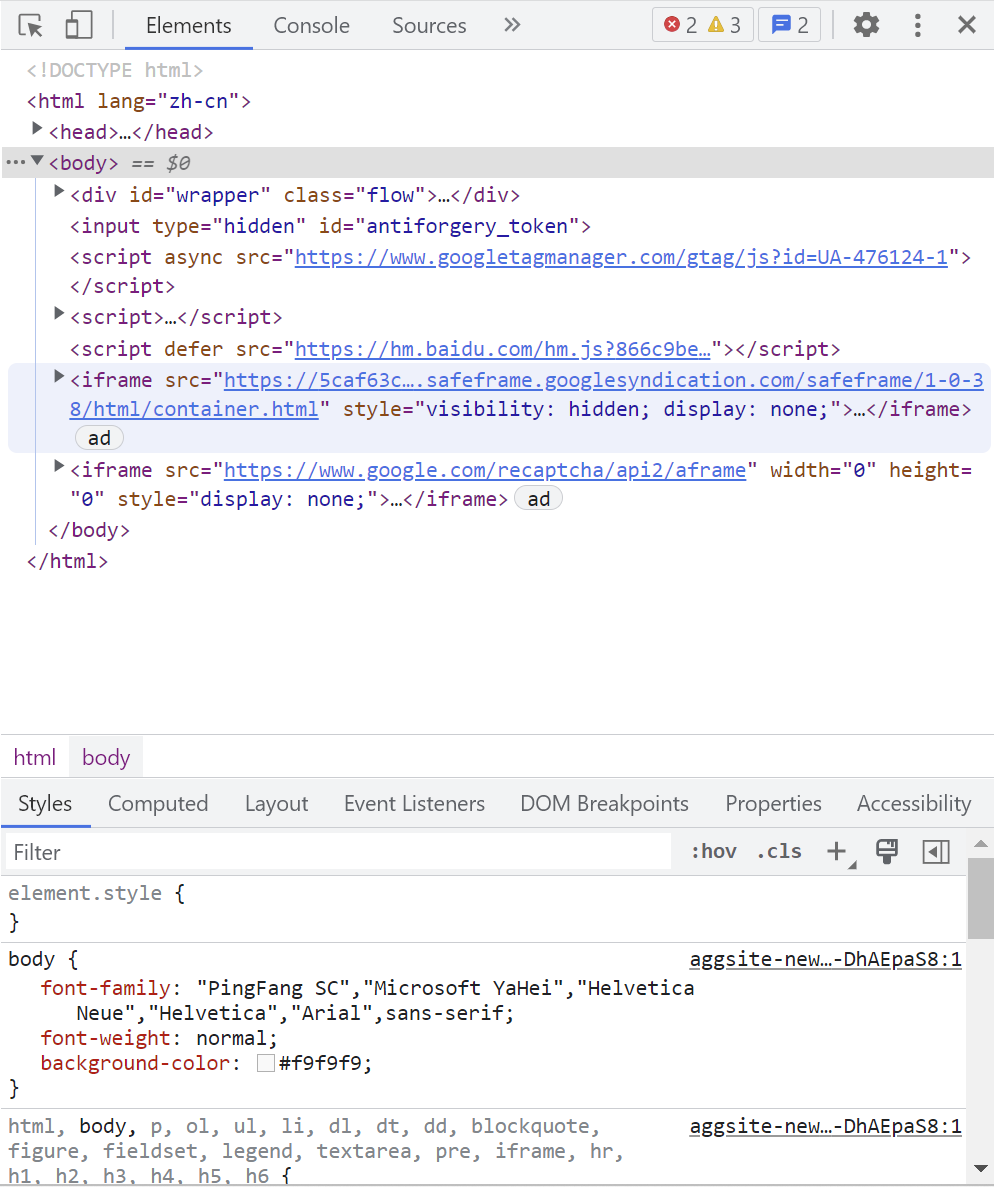
点选自己感兴趣的区域,就能够获得对应的结点。在浏览器中对结点右键,在Copy中可以看到许多选项,其中Copy selector就是获得当前结点的css选择器的筛选条件,而Copy Xpath就是获得当前结点的xpath选择器的筛选条件。
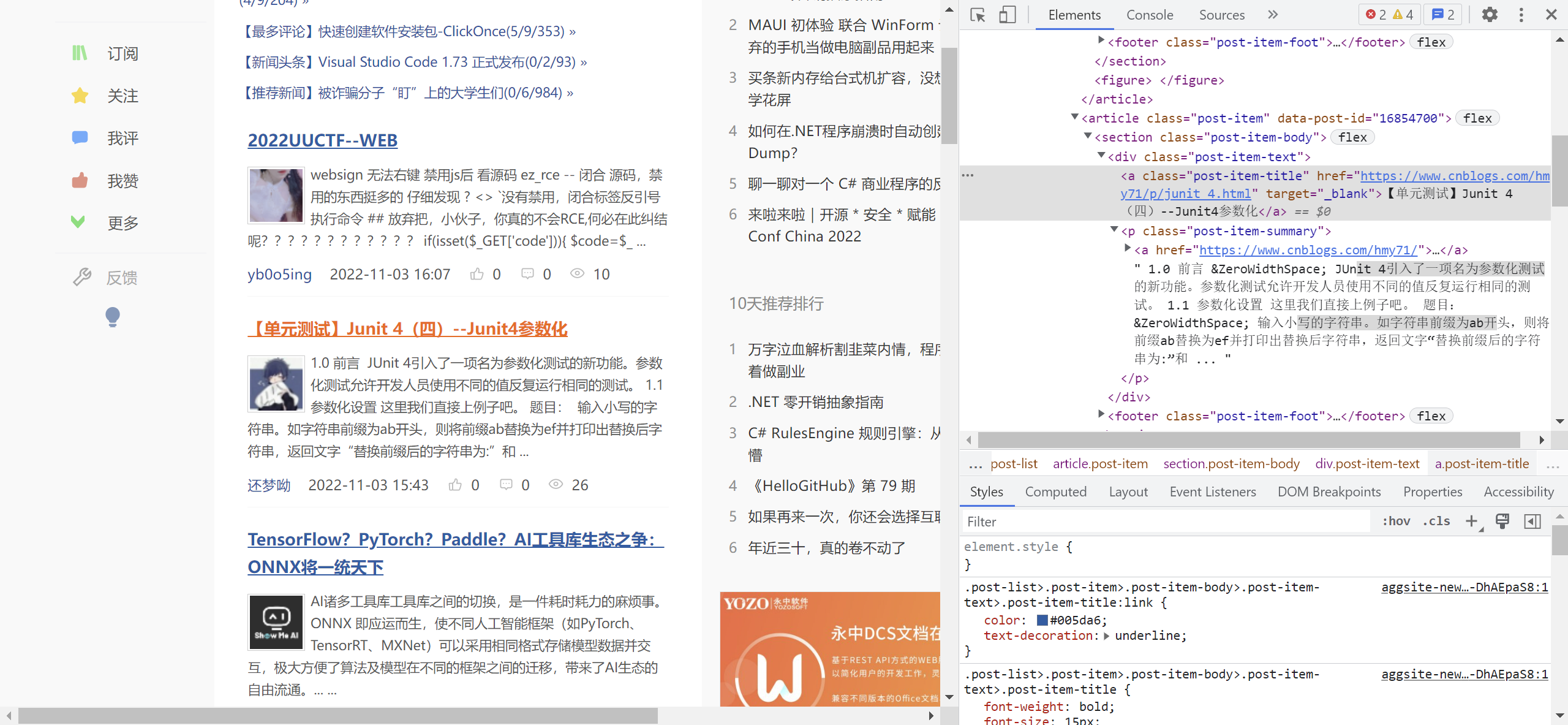
例如,如果我想获得【单元测试】JUnit 4 (四) --Junit4参数化所在结点,可以使用如下代码获得。注意css选择器的soup.select()函数与xpath的html.xpath()函数均返回一个列表,在对结点进行进一步处理之前需要先从列表中取出。
1 | # css选择器 |
在获得正确的结点后,还需要正确提取结点中的内容。如果上述结点代表的是
1 | <a class="post-item-title" href="https://www.cnblogs.com/czzj/p/16845334.html" target="_blank">C# 9.0 添加和增强的功能【基础篇】</a> |
那么如果想要获得结点中的属性内容或文本内容,可以通过如下代码实现。
1 | # css选择器 |
批量筛选内容
如果获取的内容不唯一,并且存在一定规律,就可以通过正确设置选择器的筛选条件来批量筛选内容。
与唯一筛选内容时不同,当批量筛选内容时,需要注意以下两点。
第一,css选择器的select函数以及xpath选择器的xpath函数返回的都是符合当前筛选条件的结点列表。当唯一筛选内容时,筛选条件指定唯一结点,因此列表中只有一个元素,但是当批量筛选列表时,筛选条件指定批量结点,列表中存在多个元素,可以使用循环来批量处理。
第二,css选择器构建的soup变量以及xpath选择器构建的html变量的本质都是当前网页内容的根节点,因此对于一些复杂的网页,可以先从soup或html筛选出中间结点node,再使用node.select或node.html进一步筛选。
保存网页资源
筛选得到的网页内容往往拥有其特定含义,因此需要加以妥善保存。对于轻量级的网页内容,可以使用pandas库保存在csv文件中;对于重量级的网页内容,可以根据情况保存在不同的数据库中备用。
获取网页资源 - 进阶
通常来说,大部分网页都拥有反爬虫措施,使用requests库难以爬取,需要添加headers伪装成浏览器访问,从而绕过网页的反爬虫措施并获取到正确的页面。同时,某些网站需要登录后才能显示内容页面,而html请求是不携带客户端状态信息的,因此需要添加cookies伪装成用户已登录的状态,从而获取到内容页面。
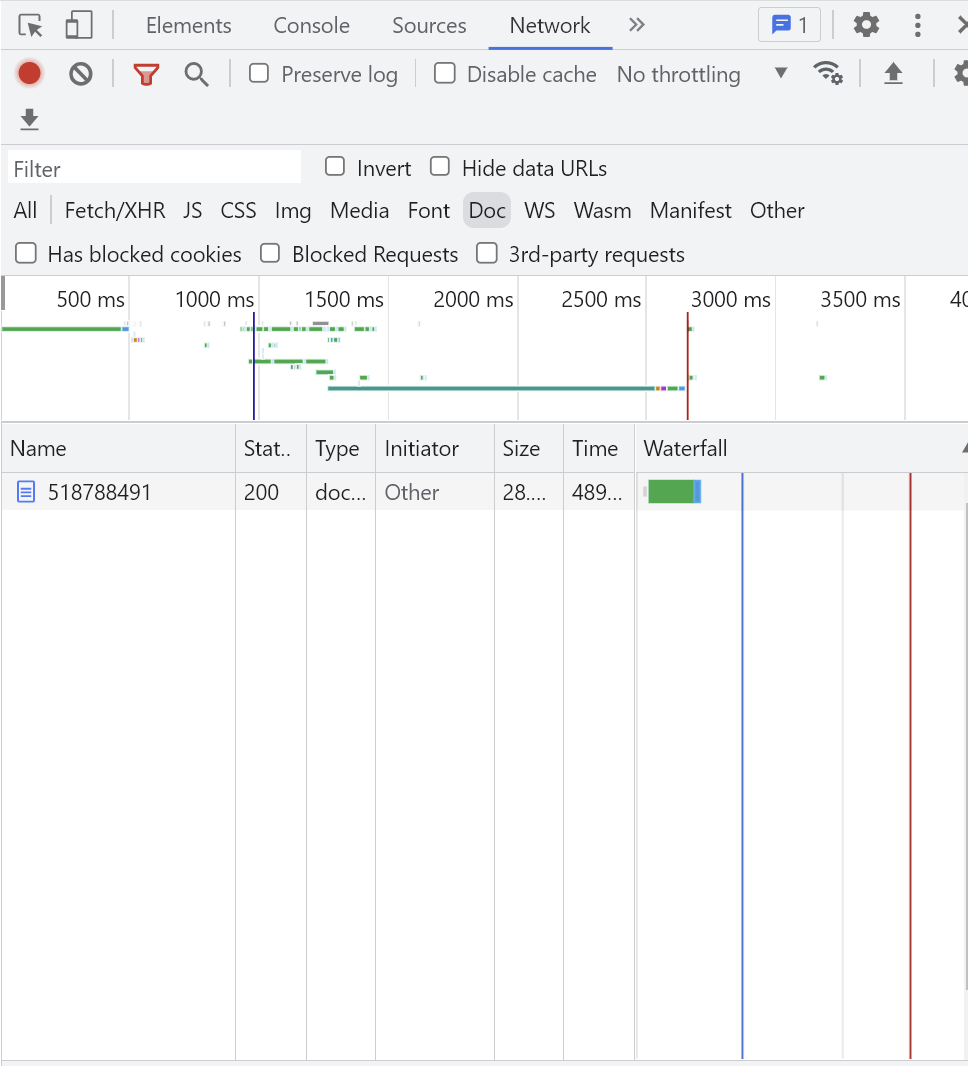
这里提供一键生成Python爬虫请求头的网站链接,具体操作如下
- 在chrome浏览器的需要爬取的网页上,依次点击:右键、检查、Network、Doc
- 刷新网页,会在Name中发现一列文件,选择其中的请求文件:右键、Copy、Copy as cURL(bash)
- 打开一键生成网站,将复制的内容粘贴到curl command框中,在下方自动生成请求头
- 复制请求头并粘贴到爬虫程序的合适位置